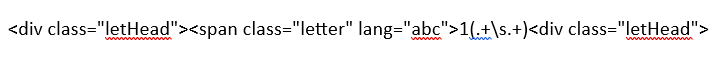In a reversals .xhtml file I want to remove an entire section of the class=“letHead”, including the reversal entries. I have tried to write a regex change and this is what I currently have:
Find:
1(.+\s.+)
Replace:
The xhtml has a CRLF that I need to account for - see screenshot from Notepad++. However, the \s in the regex in the DAB change doesn’t work as per regex101.com where it is described as being used for any whitespace character including \r\n etc. Any ideas of how to do this please?
Hi Sara,
CR and LF are separate characters, so there are two whitespace characters there.
In your Regex expression, the \s is representing one character, so it would only match on the first whitespace character (the CR). If you put a + after the \s it may work: (.+\s+.+). Since you know that it is \r\n, you could just put that in instead: (.+\r\n.+)
To get rid of the letHead AND all of the following reversal entries, you’re trying to find the right letHead and slurp up everything until the next letHead. Before we try the sledgehammer, let’s try the scalpel. If we look at the structure of the XHTML file it looks like there is a line break after the letHead, and then no more line breaks in the reversal index entries until after the next letHead. So let’s try to find this:
This finds the pertinent letHead, followed by a line break (made it optional, just in case it’s not there), followed by one or more divs with reversalindexentry, followed by the next letHead. If you use this rule, does it find and remove that letHead section?
If it does, and you want to try to go back to the sledgehammer, then try this:
This will find the pertinent letHead, and then slurp up any character (.) or line break combination (\r\n) until it gets to the next letHead. If that doesn’t work, then it may be possible that you are working on a Linux system? If so, you might try to replace the line ending (\r\n) with either \r or \n.
No guarantees, but a couple more things to try.
Jeff
Thanks Jeff, but neither the scalpel nor the sledgehammer worked.
I’m wondering if in fact the “changes” do not work on the reversal index files, but only on the lexicon source file. Can anyone confirm this? I tried another change on the reversal index file (one that did not involve any end of line markers) and nothing happened.
For the record: the belatedly-found easy way to remove the spurious reversal letter(Heads) and reversal entries is to remove the characters from the alphabet list in the Language section of DAB.