L.S.
The touch keyboard we are testing at the moment the lexical model was created based on 4 textfiles. One from our first large database of texts, the 2nd from another database of texts, the third with just the lexemes of the dictionary (those all have frequency 1) and the 4th textfile is from a database of words from exemple sentences from the same dictionary.
We have noticed that words that are frequently typed by testers, like “goodmorning” (one word in the language) does not necessarily score high in any of the 4 text databases, as do several other frequent types of greetings. So when typing “good…etc” it is not the word “goodmorning” that is proposed, but other more frequently used words like say “goodafternoon”. Now let us say “goodafternoon” has a frequency of 500 in file nr 1 and a frequency of 300 in file number 2, 1 in file number 3 and 20 in file number 4. So in all 821.
To remedy the situation, I tried to add a 5th textfile that just contains let us say problem words. So in that fifth file, I added “goodmorning” with a frequency of 822.
This change does not influence the predictive model though. Still goodafternoon is proposed first. How can I remedy this in the model?
Hi Bart. If I understand your description, a word (“goodmorning” for example) could occur in all five source files. How are you giving these files to the lexical model? Are you just concatenating these files, so that “goodmorning” appears five times, each with a frequency count? Or are you combining the files so that each word only occurs once, with the sum of the frequency counts from all the files? The lexical model definitely wants the second type of file, where each word occurs only once.
But if this doesn’t answer your question, please write again.
I am feeding it 4 separate files, where one word could in theory occur 4 times. The model allows for more files to be “fed” into the engine and this makes sense since texts can come from all kinds of databases, pre-counted and all. Have you tried working with multiple files ? (and you are right, this does not answer my question )
The compiler is supposed to sum the scores of repeated words across multiple source lists. If that is not happening, then that is a bug which we should address.
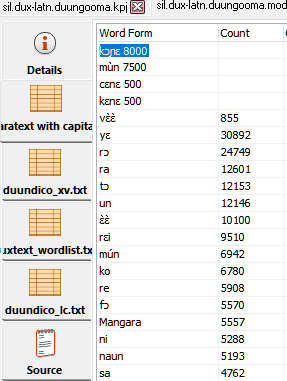
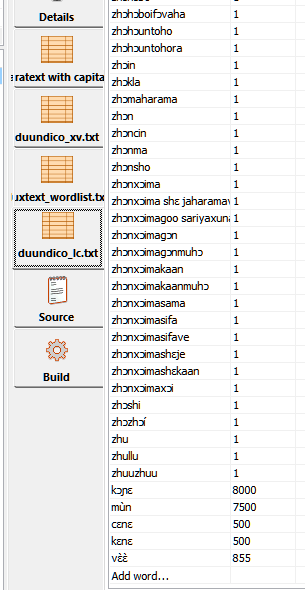
I looked at the files again and decided to add the new words in the beginning of the first file to see if by chance the 2nd, 3rd and 4th file were ignored. I did this by opening the files in KD and in the code view copying and pasting them. It turns out that there was not a real TAB between the word and the frequency. I had edited this with notepad++ and though the TAB key would produce a real tab, but when looking at the file in KD the frequency was not listed in the frequency column buy right next to the word.
But the real problem is that it seems that multiple files are taken into account, but not the duplicates in these files. If I remove the new words from the beginning of the first file and add them at the end of the forth file (see image), their “extra frequencies” are not taken into account in the model. So from that I conclude that only the first occurence in any file with the first frequency that is listed in that file is taken into account and subsequent listings are ignored. It would be nice if this can be fixed because it is very difficult to produce just one wordlist with cumulative frequencies. But if there is a tool out there that can do it, I would like to use it as a temporary solution. Thanks in advance for any tips and pointers.
@Bart_Eenkhoorn, thanks for this report and sorry for the slow reply.
Yes, I can confirm that duplicates are not merging and I am treating that as a bug. See https://github.com/keymanapp/keyman/pull/3338 for details on how we are working to solve this one.
 )
)