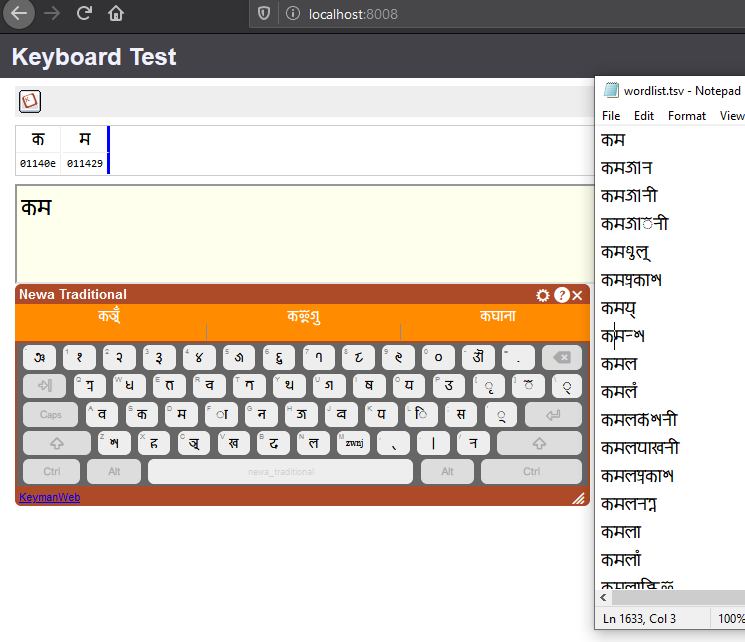
After typing two characters I was expecting words beginning with those two characters. There such words in the wordlist (on the right) however I get something else
The typed in letters are
U+1140e U+11429
The suggested words are
U+1140e U+11400 U+11443
U+1140e U+11402 U+11410 U+11438
U+1140e U+11411 U+11435 U+11411
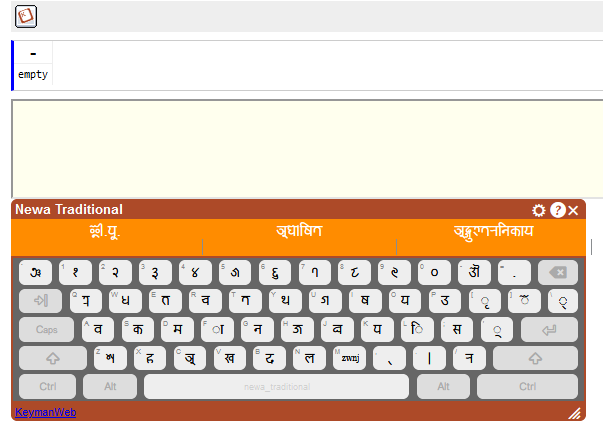
Also how does the model suggest words when nothing is typed ? This is what I get currently
May be my understanding is wrong, please let me know.
The key thing you are seeing here is that the predictive engine has a hard time when there are no word frequencies: every word is as common as every other word.
When you see unexpected suggestions, you are seeing suggested corrections. the keyboard has detected that nearby keys are probably as likely as pressing the right key. You can turn off corrections in the settings for predictive text in-app, although there is no interface for doing so in the test window.
The choices you see when nothing has been typed are essentially random – they will be whatever the compiler places ‘first’ in the compiled model; without frequencies this will not necessarily be useful.
Thank you for the insight.
Can I collect some text and compute word frequencies and append this to this word list (without frequencies) or do I need to have frequency for every word in the list ?
For repeating the same word in the wordlist: as far as I can tell, this will probably cause issues with the frequency counts, and I’m not sure what determines which frequency wins. We use that to determine what suggestions are more likely than others, so it may affect suggestion quality.
So I’m planning to delete the duplicates, but still yet to find the right tool to do so.
So I’m planning to delete the duplicates, but still yet to find the right tool to do so.
I suggest using a spreadsheet (Excel or https://sheets.google.com) to open your wordlist as a tab-separated file. Sort by the first column and then you can delete the duplicates.