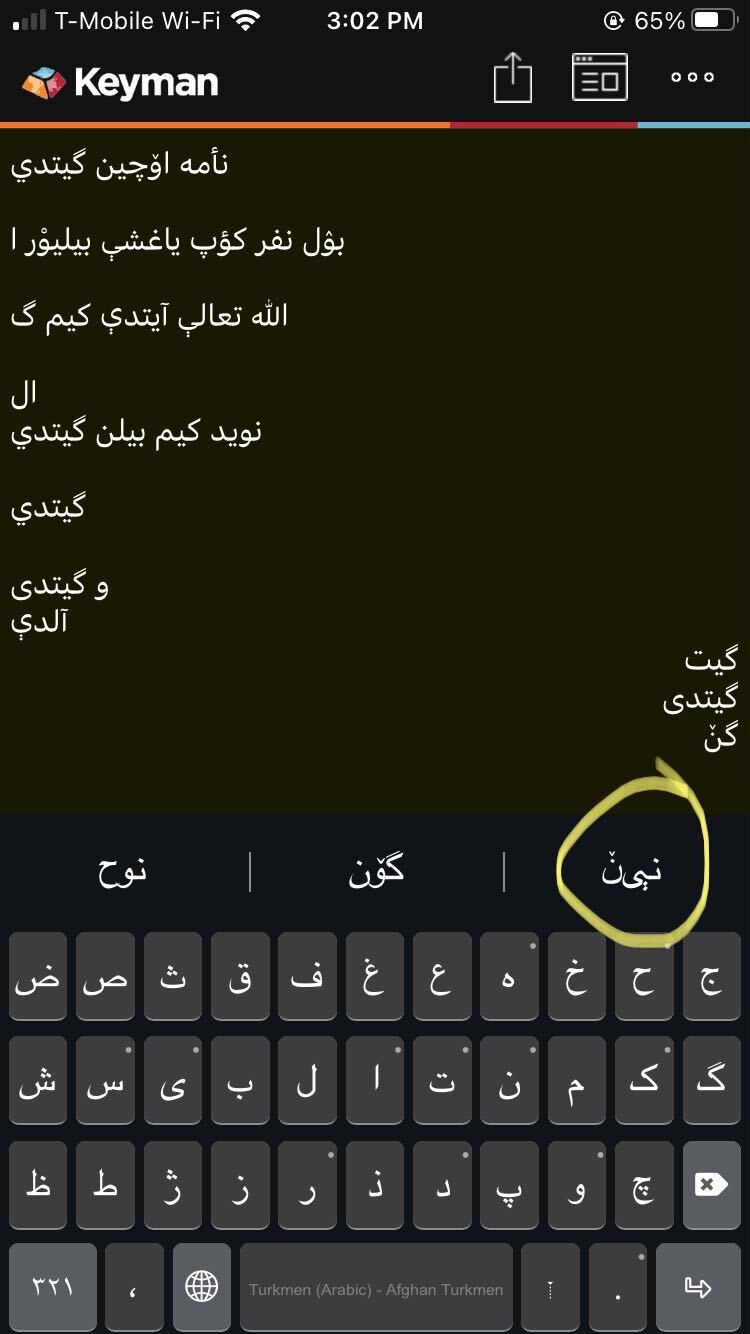
I recently created a lexical model using a tab delimited word list. Our orthography includes a number of additional Arabic script characters. When I installed the lexical model .kmp file, certain words with characters (ݩ) were not joined correctly in the typing prompt. Words with other characters (ي ې) did not appear at all in the prompt. When I looked at the .tsv wordlist source file it seemed like words with these characters were not joining correctly. I am not sure if this is a joining problem or a font display problem.
Can you find that word in the .tsv file and paste that entire line into a reply message (preferably keeping that text on a line by itself)?
Could you also tell us the font you’re using with your Keyman keyboard?
I don’t know what font is being used, but the character you are having problems with is (ݩ) U+0769. It’s not new to Unicode, but is not in the main Arabic block, and so there aren’t as many fonts that support that character. I’m wondering if it’s a font issue. Knowing what font is being used would be helpful.
These two characters (ي ې) are in the main Arabic block, but if the problem only occurs when they are next to U+0769 then it could be a font issue that the font being used does not have U+0769 or else the rendering engine doesn’t support that character. What version of Android are you using?
I don’t see your keyboard in our keyman repository so I can’t do any testing from my end.
گیدیݩ 3
Thank you for your response! This is a line from the .tsv file. I opened it with Notepad++ and copied it here. It seems to render just fine here. Not sure if that’s what you were intending.
Thank you for your response. I usually use scheherazade when I am typing with my Keyman keyboard. I am not aware of a way to set the font of the keyboard itself.
Since I am a new user, I am not able to upload my Keyman files here. How do I upload the keyboard to the Keyman repository?
I don’t know what font is being used, but the character you are having problems with is (ݩ) U+0769. It’s not new to Unicode, but is not in the main Arabic block…
There’s a chance that this detail is significant - that most of the characters are in the main Arabic block, while that one isn’t. There’s a chance that the word-breaking algorithm we use might need a little more information than is available by default to handle this scenario. If this is the issue, the lexical-model engine may be treating the U+0769 as a wordbreak, which is obviously not ideal and would almost certainly cause the problems you’re reporting.
Should I be on the right track - with our wordbreaking engine being at fault - we do have the ability to extend the wordbreaker for your model to fix the issue, and I’d be willing to work with you to figure out the extensions needed to make things work correctly.
Now, towards all of this… I don’t read or type Arabic, so it would help to have some example words I could copy and paste to test this hypothesis. I can check the wordbreaking angle without having to manually type it, but I do need to have some good example words where problems currently arise. Again, make sure I can select it directly for copy-and-paste operations.
I can see some text in the screenshot, true, but it would take me quite a while to figure out how to type that myself. (Arabic is RTL instead of LTR, and some of the letters look very similar to my untrained eye.) In case I do end up needing to manually type it, being clear about which keys to press in which order would also help.
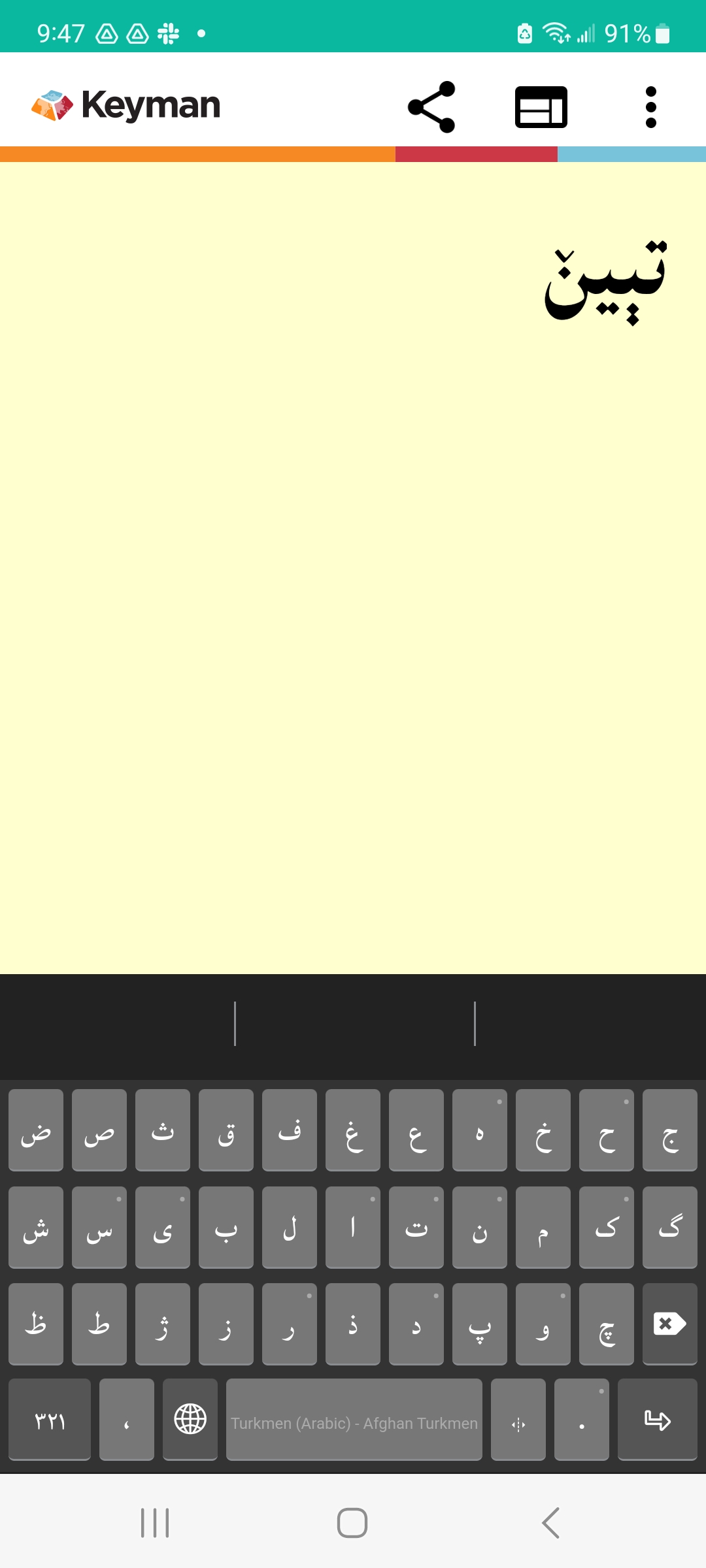
I think the issue was related to the font. Here’s what I’m getting now. However, I’ll send you both the source files as fixed up separately.
Hi Joshua,
The joining issue was caused by no font being bundled with the keyboard. After Lorna corrected that, I have not seen any other issues. If I do see word break issues with (ݩ) I will certainly let you know.
Thanks!
1 Like
This conversation is closed. You may wish to create a new topic if run into another issue.
Thank you!