Sometimes characters do not display correctly in one or more programs due to language differences and renderings…
Recently, we have been getting many languages from Asia and India region. We have found out that there are Font Display issues if the translation text is exported to Microsoft Programs such as Word or Excel because these languages have combination of letters and combining marks. Unfortunately, these languages display correctly in ParaText (no errors are detected or shown) so we do not know that there is an issue until after we export the text. In other words, Paratext displays combining characters correctly but other programs do not.
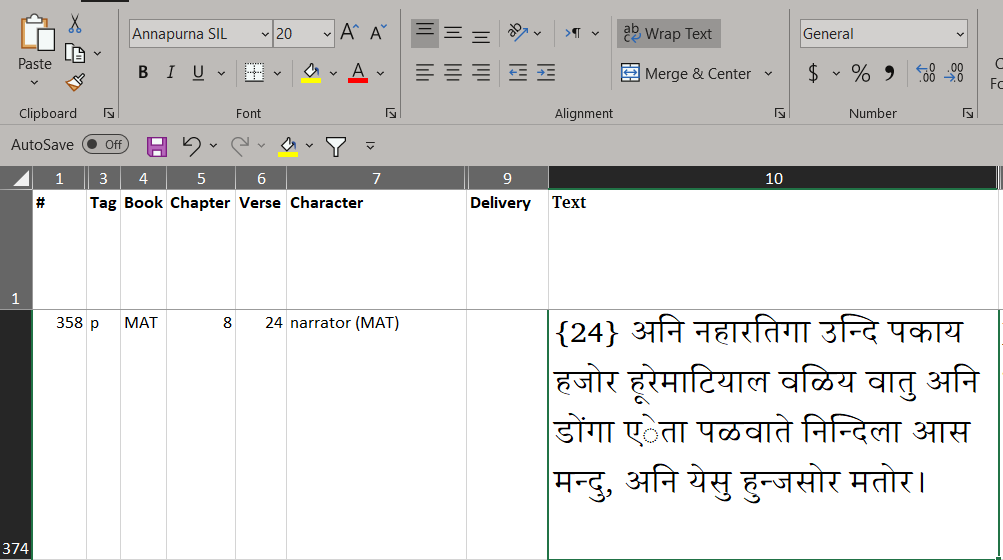
This issue is common with texts from the India region (especially Devangari).
Have you tried using LibreOffice Calc (instead of Excel)? That might be a viable solution, but even if not, it might help identify where the problem lies.
(PS: Love the Luke 5:26 quote!)
Short answer: I think you want the Devanagari character U+0910.
Putting a vowel sign (in this case 0947) on an independent vowel (090F) is not a valid combination. Vowel signs are used to modify the inherent vowel in a consonant cluster.
So why does it work in some apps and not others? The issue here come down to two “competing” rendering systems. One is OpenType which is driven by the DirectWrite/Uniscribe rendering system by Microsoft in their products. The other is the Graphite rendering system created by us (SIL) and used in SIL apps and the LibreOffice suite. Microsoft will not render any combination of characters they think are invalid, which is why you are getting the dotted circles. The SIL model is more liberal when it comes to rendering combinations but in this case I think the Graphite code should have been more restrictive. I’ll need to look into that once I work on the Annapurna project later this year.
Summary: If you exchange the U+090F U+0947 characters for the U+0910 character in Paratext and then export to Word or Excel, it should work. If for some reason it doesn’t work, then there is an issue with the export process.
You should replace the U+090F U+0947 characters for the U+0910 character in Paratext as I mentioned in my reply earlier. The U+090F U+0947 combination is not valid and needs to be corrected in the Graphite code for Annapurna SIL. We’ll work on correcting that later this year.
As Andrew pointed out, there is font substitution happening when you export. The spreadsheet screenshots show a font different from Annapurna SIL. That is a secondary issue. You need to use U+0910 to correct the primary issue.
For this situation, I agree with @joncoblentz that you are seeing the output from Microsoft DirectWrite as it process the OpenType in whatever font you are using. You should keep in mind that Microsoft DirectWrite is not the only OpenType implementation. HarfBuzz is another one, which is used in Chrome (but maybe not on iOS) and in Microsoft Edge and other programs as well.
Table 12-1 on page 450 of the chapter on Devanagari in the Unicode Standard lists several combinations of characters that should not be used. The combination of codepoints that you are trying to use are mentioned here, along with many other combinations to avoid.
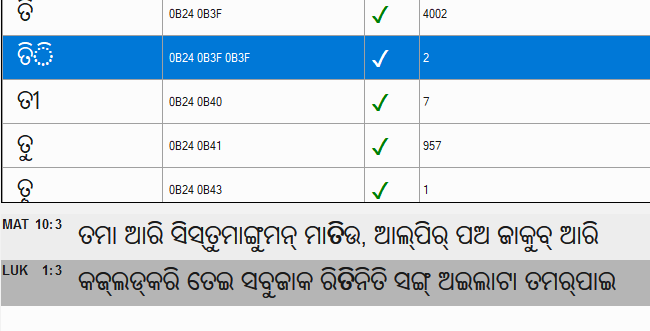
It looks like the various signs (CANDRABINDU and various vowel signs) are duplicated, which is causing the dotted circle to appear. The solution is not to have duplicated signs. I am curious what process generated the duplicated signs (typing, converted from legacy encoded fonts, or transliterated from another script stored in Unicode)?
It does not seem that ParaText flags the duplicated signs as errors and most of them are marked as “Valid” by the text/project owner (which is not me). Unless you open the Character inventory and look for them or copy the text into MS Word, everything looks fine…
While the text may look fine in some programs, I still say the text is incorrect, according to the rules of Oriya (Odia) script. Spell checking, searching, and sorting will be hindered by this issues. If Paratext does not see the issue as an error I suspect that is because Paratext was not programmed to check for Indic specific issues (which is what we have here). I would ask the project owner what he meant by having two signs in a row. Did he want them to stack on top of each other? Such behaviour is needed to support U+0B55 ORIYA SIGN OVERLINE which a font that I made (from Noto) handles. That font should cause the duplicated U+0B3F ORIYA VOWEL SIGN I to stack on top of each other. So if U+0B55 is needed, then that would be an exception to having two signs in a row.

 /g/personal/purquidez_fcbhmail_org/ER8Kr8NyehJBjskWm4Hs8JgBUFz8VPH0SaAqmx4RTtwIVw?e=G01l7M
/g/personal/purquidez_fcbhmail_org/ER8Kr8NyehJBjskWm4Hs8JgBUFz8VPH0SaAqmx4RTtwIVw?e=G01l7M