I need to know the “rules” for the word lists used in a lexical model. Specifically, what happens if the word appears in both lowercase and uppercase forms? Are they combined or treated separately? If the latter, how does that play with the new languageUsesCasing flag?
I’m assuming that the bugs mentioned last year regarding duplicated words in one list have been resolved? And I believe a duplicated word in a separate list would just add in to the count with other lists?
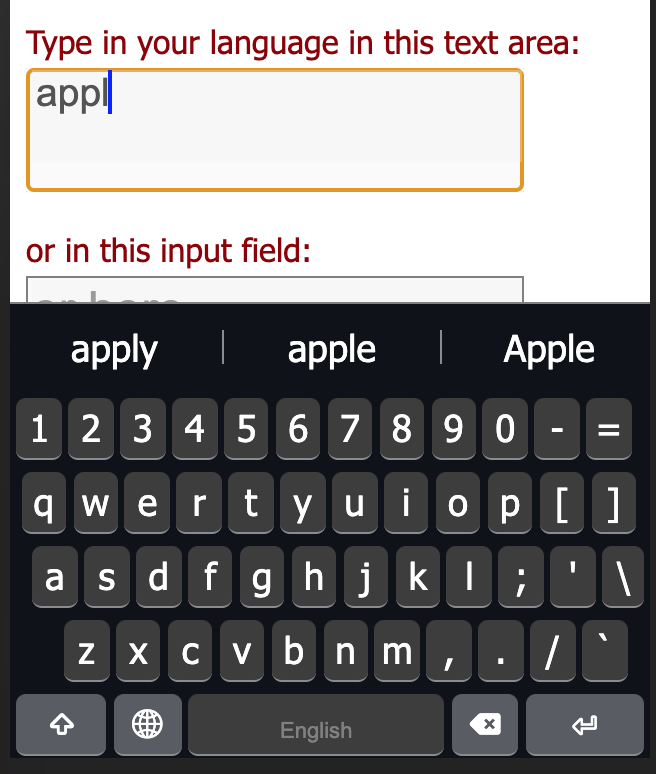
In this English example, this allows predicting either “Apple” (the company, a proper noun) or “apple” (the fruit). Here, “apple” has a higher frequency count than “Apple”, so it appears first.
(Sadly, “apple” is actually missing from our current default English model. Might have to fix that.)
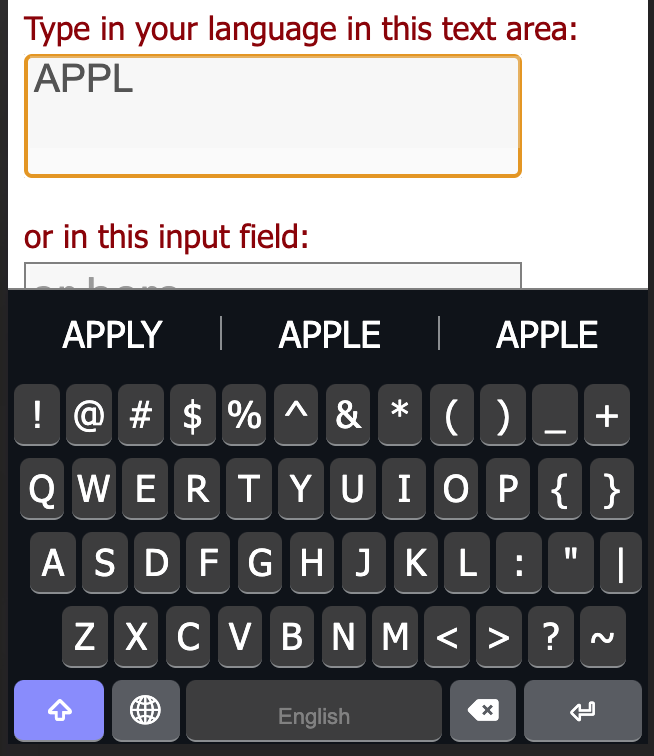
A word’s appearance within the wordlist will be its default lowercase form for suggestions. So, if you put old “MacDonald” (had a farm…) in your wordlist, typing “macdonald” would actually suggest “MacDonald”. If a word has two different capitalization patterns, the compiler assume that the two different patterns are intentional and should be treated as different words as far as predictive text is concerned.
At the moment, since the two are considered different words, we don’t yet have anything in place to combine the two when applied capitalization causes the words to become identical. We should be able to fix that in time for release, though.