I’m in the middle of a workshop. Got participants typing their languages using Vietnamese basic keyboard. Most work fine. But on 1 machine I cannot type any of the special characters that should appear when typing the number keys: ăâêôòỏõóõóọ
I’m pretty sure there’s a simple fix, there must be a hot key to switch between typing numbers and the symbols above but I can’t find it.
Can you provide additional info about the machine have issues?
Which OS? Windows 10, Mac?
Keyman version?
What application are you trying to type in?
In Keyman Configuration, please confirm you’ve got
Vietnamese Basic version 1.1 selected, for the Language Vietnamese (VI).
The keyboard icon on the lower right should also display “VI”
Hi Darcy. It’s Windows 10. Typing in Word and Bloom and Keyman text editor. VI icon is there - the keyboard is selected. Latest KM 12. I actually took an exe file with me, clicked to install it, and it offered to install a more recent one, 12 point something.
That’s one of the keyboards that uses Keyman’s default hotkeys (RALT SHIFT K, RALT SHIFT O, RALT SHIFT M). You need to change or turn off those hotkeys in Keyman configuration. It doesn’t sound like what’s causing your problem, but if your user tried those keys then it will get confusing quickly. I’d disable them, then turn Keyman off and on and see if it helps.
Thanks. I’ve sent in the diagnostic report (turning off hot keys didn’t solve the issue). However, I have a feeling the issue is something to do with the guy’s computer. The keyboard works fine on other machines. On this machine, even when I remove the VIE keyboard (already available through Windows 10 language settings) then set the input language to English, it still produced V characters. For example, typing a vowel followed by ‘s’ puts a district above the vowel (not v + ‘s’), or when I double tap ‘e’ it produces ‘e’ + diacritic. I think this is the excited behaviour of the VIE keyboard but it’s happening even when I attempt to remove that keyboard and select ENG. Additionally, when I removed VIE, then clicked on input method icon on bottom task bar, ENG and VIE we’re there, VI (Keyman keyboard) was fine, even though it was VIE I removed, not VI. Additionally again, I removed the VIE keyboard yesterday but it reappeared on restart. All this to say, is battening on this particular machine and no others and there are these additional behaviours.
I’m not sure what the VIE keyboard is? But it does sound like it is taking over the keyboard and not allowing Keyman to work as it should. I would hope that if you are able to remove that keyboard, things would work correctly.
According to the diagnostic report, however, Windows is reporting only US English keyboard installed and no Keyman keyboards registered. This may just be because you didn’t have Keyman running at the time you took the report?
The VIE keyboard is what appeared when adding a Vietnamese keyboard through Windows language preferences - but it refused to be deleted properly. I wonder if this had something to do with the set region and system language (but the system language was English). I think Keyman was running. Anyway, I wasn’t able to make typing easier for them but they worked around it. Workshop is finished now and they made a few books and other texts. Thanks for looking into it.
I am experiencing a similar problem with the Keyman Telex keyboard. I am using Windows 11 typing in Fieldworks 9.1.19.1290, and I have removed the Windows Vietnamese Telex keyboard to avoid conflicts.
My problem is this: Although single diacritics work fine (đ, á, à, ã, ả, ạ, ơ, ư, etc.), combining diacritics (ấ, ở, ộ, etc.) do not output as expected. For example:
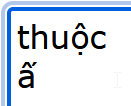
Keystrokes: thuoojc
Actual output: thuôjc
Desired output: thuộc
Perhaps there is a configuration issue that I need help with. I am new to Keyman. Any help would be appreciated.
I am using Noto Serif (version unknown). The problem also occurs for Times New Roman (which MS says is version 7.01 in Windows 11).
Keyman is totally new to me. After I discovered that I could not use it in any apps other than FLEx, I discovered the Keyman text editor. And in there it types correctly. So I am wondering if this is a bug in FLEx.
You should be able to use Keyman in most apps that allow you to type. You may have to select the keyboard you want for each app, using the Keyman icon in the system tray (next to the date/time display). (Very few apps know how to switch keyboards as FLEx does.)
I wonder if you could send me a copy of your FLEx project, or make it available to me somehow, so I could look at what the problem might be. [david_rowe at sil.org]
Alternatively, could you try changing the font to Charis SIL to see if the problem is still there?
Just sent an email. Thanks again for helping me with this. I don’t really need Keyman to work for any other apps. I was just trying to confirm that it was working properly outside of FLEx.
Summary of off-list investigations plus help from Ann (FLEx help desk): Internally FLEx works with decomposed data and this keyboard is producing composed data. It’s not clear what the best solution might be.
The best solution is for Keyman to provide composed data to the keyboard. But that’s a long way off.
An interim is to update the keyboard to recognise both decomposed and composed data on the context, and emit the corresponding composed data on the output. We have done this with other keyboards. My only concern here is that Vietnamese Telex is already a huuuge keyboard and I wouldn’t want to make it much larger!
(It may be possible to do a transform group for the keyboard that composes decomposed diacritics, before passing control into the main group? A good research project, would love to take it on but not possible this week…)
Long term, I suspect that the best solution is for the keyboard to indicate what normalisation form should be emitted, and for the user to be able to change it as required. I always find that for everyday typing NFC is fine, but there are times when I do require NFD or even other formats like Windows Vietnamese or MARC21.
I try to be flexible when I design internal keyboard layouts, something that I intend to incorporate in layouts I need to update t=for the keyboard repo. Although considering the direction LDML keyboards are likely to take, and what you indicated above, I suspect that for quite a few cases I will need to post-process text generated by the keyboards when NFC doesn’t fit the bill.
This should be an engine-level setting, ideally, buried in a dialog box titled “For Andrew Cunningham Only” Ideally it doesn’t need to be catered to in the keyboards. The keyboards themselves should be able to emit NFC, NFD, or even mixed, and let the engine sort out what the apps need. (In fact, in some ways, perhaps this should be an API control available to apps rather than to the user?)
@Marc I was thinking in terms of library catalogues and ALA-LC romanisation and MARC21 character requirements, esp for authorities files, where most characters are decomposed except for certain specific Latin, Cyrillic and Arabic characters which are precomposed while the rest is decomposed, so hybrid between NFC and NFD. I don’t fiddle with normalisation forms unless there is a need. Esp with training materials.