L.S.
I am testing a lexical model and it looks very good. What I would like to improve is:
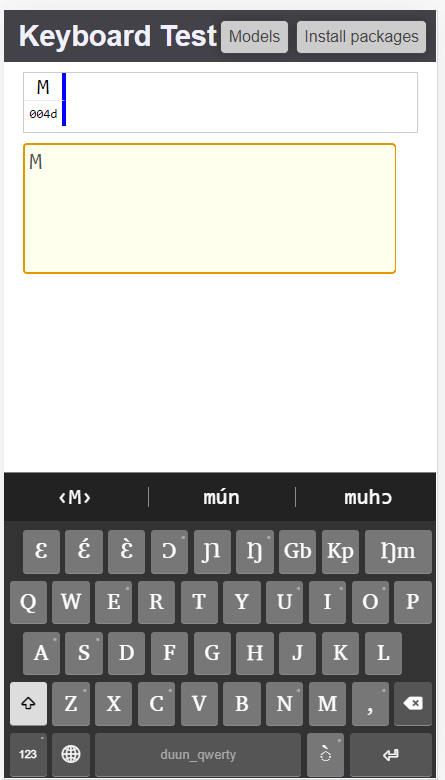
a. Capitals to remain capitals if the predicted word is selected. Exemple,
I start a sentence with M and get mún as suggestion, which is good. This is the word I want, but with a capital. So I select that and get mún in lower case. How can the capital M be preserved?
a. We currently have plans to attack this in the next couple of months. We’ll need to take a little bit of time to analyze the affects this would have across different language families, but plan to include ways for model developers to specify such behavior.
b. Not at this time; that’s quite far off for us due to limited development resources.
Thanks for that. I have since found out that PrimerPrep is partly to blame because it changed all words from my text database to lower case. For primer preparation it does indeed not matter (Mún and mún are the same words) but it does matter for the Lexical Model. Unfortunately for proper nouns, I am now only presented with lower case names. For example “hello john, how are you, how is queen elisabeth” etc, even worse “i pray to god you will be well soon”.
If PrimerPrep could be made to keep the capitals and count Capitalised words as separate that would be a big advantage.
I am using a second wordlist, prepared by other software and here the captals are respected …
Yes, PrimerPrep is partly to blame for the reasons you mentioned. I’m playing with the possibility of PrimerPrep keeping capitalized-only words as capitalized, but if a word ever appears in lowercase, it would just keep the lowercase version. However, I need to carefully consider the implications of this change, to make sure that I am not sabotaging the needs of literacy folks (the program’s primary purpose). I have created a pre-alpha version of PrimerPrep which should be able to keep capitalization for words that are ONLY capitalized in the source texts. I’m not ready for other people to see this version yet, but if you send me the source text(s) that you used to create your word list, I can try to create a new version of the word list for you that has some capitalization.
Note that this would still be an imperfect solution. “Queen Elisabeth” for example would be able to capitalize Elisabeth, but queen might very well appear lowercase somewhere in your texts, and so not appear capitalized in the word list. Or even your reference to “God” - if somewhere in your texts you mention some other “god”, then it won’t be capitalized in the word list. Or if there is a fairly rare word that only appears in your texts at the beginning of a sentence, then it will only appear capitalized in the word list. Like if I analyzed this post, the word “Note” would probably be capitalized in the word list, because it doesn’t appear anywhere (I believe) in lowercase.
Thanks for replying Jeff. For the sake of the model, should not all capitalised words be kept as is ? Why only those that have no lowercase equivalent? We could be dealing with homonyms. I know several languages where the word for rain and God are the same for instance. One spelled with capital, the other not. All my lists are toolbox files, do you know if there is a way to do this in toolbox ?
Hmmm… I think this is something that @Marc and the Keyman team should weigh in on. On most predictive text keyboards that I’ve seen, if you start typing with a capital letter, then the keyboard will propose words from its word list that it has itself capitalized; I’m pretty sure that those capitalized words aren’t in the word list, but that the keyboard produced them on the fly. So if I’m starting a sentence, “Howe…” it will suggest “However”, not “however”. If the keyboard only offers the lowercase and I tap on it, I would need to go back and capitalize the word later (if I want to obey capitalization rules…). I think the Keyman predictive text keyboards currently don’t produce capitals from lowercase words, but I think they should, and it seems to me like maybe that should be a fairly high priority for the team.
My take is that all lowercase words in the word list should be allowed to be capitalized by the keyboard, but that anything that is capitalized in the list should only be allowed to be uppercase - which would serve to maintain proper names. (And of course, if you start typing something in lowercase, but it is only capitalized in the word list, that should also be proposed. E.g. typeing “keym…” should propose “Keyman”.)
If we keep capitalized words as is from the texts you analyze (what you seem to be suggesting), then certain words would be capitalized in the list, depending on the texts you analyze, but others wouldn’t. Again taking the example of this post, the word list would have “Again”, “If”, “My”, “So”… a pretty limited inventory. So I think the predictive keyboard needs to be able to produce an uppercase version of any word in the word list, but not a lowercase version of any capitalized word in the word list.
How did you produce your word list with PrimerPrep in the first place? If PrimerPrep sees an SFM-marked input file (like a Toolbox database), it will ask you how you want to treat it - basically allows you to process only certain SFMs, or exclude certain SFMs. Is that what you did? There are also other ways to pre-process or filter a Toolbox database. If you send me a sample offline, I might be able to give some advice.
I looked at some tools online that keep capitals as they are and going to try that. Toolbox does produce a wordlist quite easily. I had forgotton how powerfull the textdatabase abilities of toolbox are
The easiest tool that also keeps the capitals is: Word Frequency Counter
and a great linguistic analyser tool that also does N-grams, but does not keep the capitals:
We’ve got a lot of competing priorities – and very limited resources to tackle them! This is on our agenda to improve, as Joshua Horton noted above.
We need to do some analysis on the possible scenarios because it’s not something that can be applied to all scripts with casing – some languages do not use capitals at the start of sentences, and at least one language uses only capitals. So whatever we do, we need to make it controllable by the model developer.
In order to prepare, I think you should make sure that the words in your wordlist are in the intended form, ignoring start-of-sentence rules. So, ‘London’ should be capitalized, but ‘if’ should not be. ‘God’ is a fun case as it can be either capitalised or not, depending on context.
Just to be clear… I don’t think Keyman needs to figure out whether a capital letter needs to be used or not in a given context, e.g. at the beginning of a sentence. It just needs to be able to produce a capitalized word from a lowercase word in the word list, if the user starts the word with a capital letter. That’s a much simpler requirement! And I would think that just using the data in the Unicode Character Database (the presence or not of the Simple_Uppercase_Mapping and Simple_Lowercase_Mapping properties) would make that task not too onerous.
For the language that uses only capitals, the word list just needs to have all of its words fully capitalized. For other languages, Keyman should be able to produce an uppercase equivalent of lowercase words in the word list, but uppercase words would not be turned to lowercase - they would only be suggested in their uppercase form. Languages that don’t use capitalization wouldn’t be affected, since they don’t have the case properties in the UCD.
It’s not quite that simple unfortunately. Generally, we can start with the UCD case properties but we do need to allow override.
For example the Turkic languages that use dotless and dotted i mean that the casing rules need to be specific to language, not to script. From memory, there are some Canadian languages that have specific letters that are never upper-cased, although most are. We can’t rely on standards data for a lot of this, because there is no standards data for many of the languages we work with!
While this isn’t necessary, it is an optimisation and rounding out of capitalisation functionality for users that is very welcome. We may implement this aspect of the functionality in a different timeframe, but I want the design to cater to it.
We are working through this stuff in the issue I referenced above and plan to finish the design and implement as much as we can of it in v14 of Keyman – the timeline currently shows us working on this in August (although that’s a bit rubbery due to various external pressures that we are all experiencing).
Hi all
Very interesting discussion. I actuality read every topic related to capitalization. I wanted to know how we can make the keyboard start will CAPS. My keyboard (Fulah touch layout) starts with minuscules and I always have to press shift before writing the first sentence.
Thats only when I first start the keyboard.
Need help on solving that.
Cheers
Ibrahima
Thanks a lot Marc
That would be great.
I was wondering what would happen if I started the touch layout code with shift state first, then lower case last?
Hi Marc
I found out that cutting and pasting “shift” state at the beginning of the file is quite tricky. Easy to miss out a curly bracket or a comma and mess up with code. Is there a good method to do so?
“No problem too big, no question too small” (I may have been watching too much Paw Patrol with my son)
Unfortunately, there isn’t a very easy way within Keyman Developer itself. You might find it helpful to use an online JSON editor such as https://jsoneditoronline.org/ – just copy and paste – as it provides better feedback for JSON structural issues.
Thanks a lot Marc,
I actually did put shift on the first layer on both phone and tablet. But I still have default state on keyboard start up.
So it seems putting “Shift” at the beginning of code didn’t work. It is reflected on design mode though.
There is another way but it’s a little messy: swap the default and the shift layer names without changing the content of the layers. But then you will need to update the modifiers for each key to default for the “shift” layer (which is not really “shift” any more), and vice-versa (each key would need the modifier ‘shift’ for the ‘default’ layer).
It’s not a great solution, so you may prefer to wait for the proper fix coming in 15.0.