Isn’t there a little too much space in pairs уд, ул, ӱд and ӱл in Charis and Gentium?
Yes. We have not added any Cyrillic kerning. It’s needed, but we haven’t had the time in the midst of many other requests.
Is it safe to say, then, this will be dealt with in a future release?
We recognize that it’s needed, but I cannot guarantee that we will add it or when it will be added if we do. I’ve added it to our list of requests, but be aware that there are already requests for hundreds of additional characters that will get a higher priority.
Kerning is very language-specific. What language(s) are you mostly interested in?
I look forward to the next updates, hoping that the Cyrillic blocks will receive your attention.
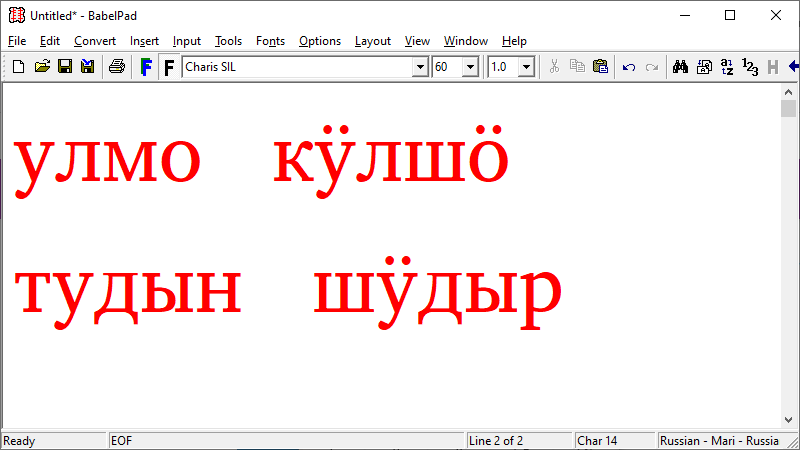
I spend most of my time with the Uralic languages. The four red words in the screenshot come from the Meadow Mari language, which has been the focus of my interest recently.
That’s very helpful. The main problem with kerning is knowing what pairs can occur. If we were mainly interested in majority languages (English, Russian, etc.) there is a lot of data available, but it gets much more difficult when our focus is the hundreds of other languages that use the Latin and Cyrillic scripts. We can’t kern every theoretically possible sequence.
For this reason we have no kerning in Charis, even for Latin, and only very limited kerning in Gentium.
Some of our users add kerning themselves for specific languages, either by adding them to the font directly (which is allowed with the SIL Open Font License) or using macros or scripts in publishing software.
What data would you need to even start thinking about adding kerning to Charis and Gentium?
We’d need frequency data on the most common character pairs in a wide variety of languages, that would give an equal balance between major languages (Russian, Bulgarian) and others (Mari). We could then identify the most common troublesome letters (like the two you’ve mentioned) and focus on combinations that include them.
One possible resource is the Gentium TUG project, which would provide some major language kerning for Latin and Cyrillic.
Even with this data, the larger problem is that other priority requests usually are more important to us, such as adding support for Unicode 15 characters or a new feature needed for a particular language.
I only know of one downloadable Meadow Mari corpus that was created for Yandex Translate some time ago. It consists of a bunch of TXT files, including one containing 370 thousand sentences in Mari. I don’t have a tool to extract any data on the digraph frequency, but maybe you could make some use of it.
I know there exist corpora of other Uralic languages, e.g. Volga-Kama Corpora, but I don’t know if they are downloadable or usable in any other way that could help determine the digraph frequency.